
Retrieval-Augmented Generation (RAG) has become the go-to architecture for building LLM-powered document question answering systems. But most teams stop at the baseline implementation and never realize how much accuracy they’re leaving on the table. This guide covers 12 concrete upgrades – from hybrid retrieval and reranking to GraphRAG and self-correcting pipelines – that can dramatically improve your RAG system’s performance.
If your “document Q&A” looks like:
chunk → embed → top-k → stuff into prompt → answer
…you’re running the baseline. It works for simple fact lookups, but it breaks (often silently) on:
- ambiguous chunks (lost titles/sections/”what is this referring to?”)
- multi-step questions (“connect the dots” across pages/docs)
- global questions (“summarize themes across the corpus”)
- tables/figures/layout-heavy PDFs
- retrieval noise (top-k contains “kinda related” chunks that derail the answer)
State-of-the-art Document QA is not one trick. It’s a stack: better indexing, smarter retrieval, reranking, context shaping, self-correction, and evaluation loops.
What Vanilla RAG Gets Wrong and Why It Plateaus
Vanilla RAG assumes:
- Embeddings will surface the right chunks.
- Top-k chunks will contain enough evidence.
- The model will reliably use that evidence.
But the biggest failure mode is retrieval — not the model.
The Lost Context Problem in RAG Chunking
A chunk like “Revenue grew 3% QoQ” is useless if you removed the who/when/which report.
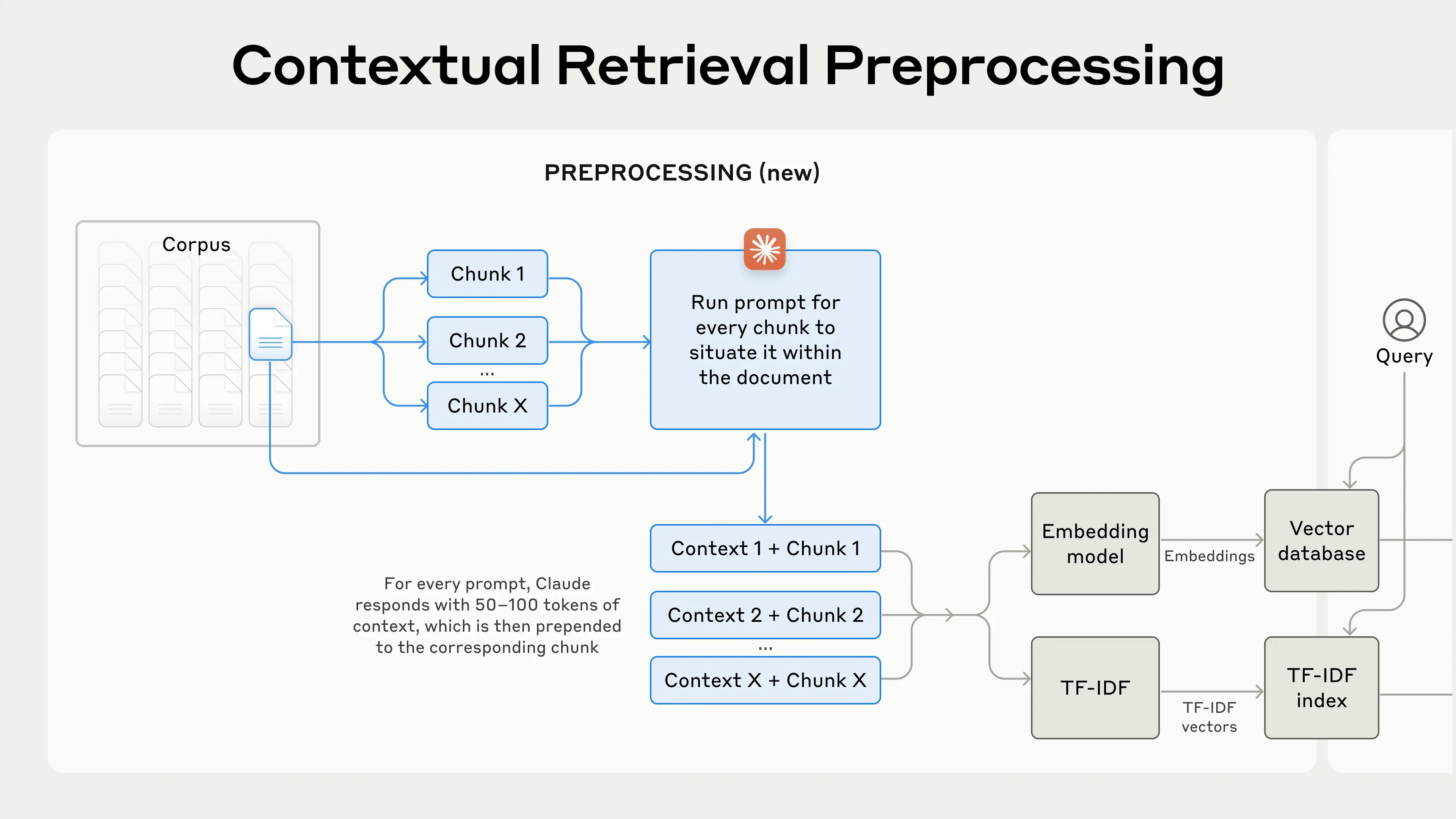
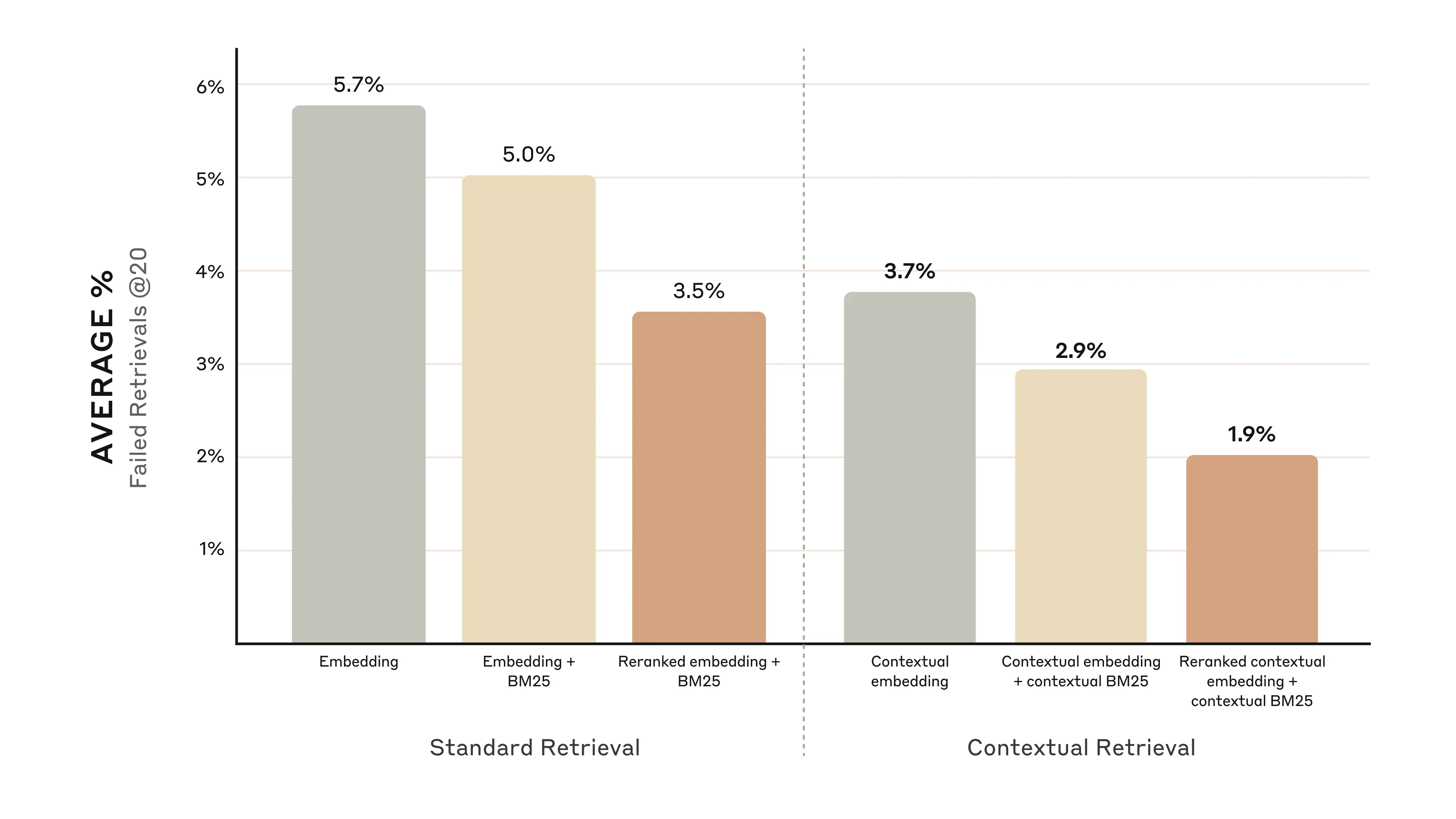
Contextual Retrieval is a simple fix: you prepend chunk-specific context (doc title, section, surrounding summary, entity/time hints) before embedding so the vector “knows what the chunk is about.”
The RAG Maturity Ladder: From Naive to Advanced Retrieval
Think of modern Document QA as levels:
Level 0 — Naive / Vanilla RAG
- fixed chunking (often by character length)
- single vector index
- top-k retrieval
- prompt stuffing
Level 1 — Advanced Retrieval Stack (highest ROI)
- hybrid retrieval (BM25 + embeddings)
- reranking (cross-encoder / LLM reranker)
- query rewriting / multi-query
- contextual chunk embeddings
- dedupe + compression before generation
Level 2 — Modular / “Systems RAG”
- hierarchical retrieval (retrieve summaries + details)
- graph / entity retrieval for “connect the dots”
- multi-vector / late interaction retrievers
- self-correcting RAG (retrieval evaluator + critique loop)
- evaluation harness + regression tests
12 RAG Improvements That Outperform Vanilla Retrieval
A) Ingestion & Indexing upgrades
1) Structure-aware chunking (not fixed-size slicing)
Use document structure:
- headings → sections → paragraphs
- table cells / captions as first-class units
- page anchors + citation IDs
Why it matters: retrieval improves when chunks align with semantic boundaries.
2) “Contextual Embeddings” (fix chunk ambiguity)
Before embedding, prepend compact context like:
- doc title + section title
- a 1–2 sentence “what is this chunk about?”
- entity/time normalization hints
This specifically targets “chunk is relevant but unreadable alone.”
3) Multi-index your corpus (not one vector store)
Maintain multiple views:
- paragraph-level index (precision)
- section-level index (context)
- document-level summaries (recall + global answers)
B) Retrieval upgrades
4) Hybrid retrieval (BM25 + dense embeddings)
Dense embeddings catch semantics; BM25 catches exact terms and rare identifiers. A strong pattern is:
- retrieve candidates from BM25 and dense
- fuse results (e.g., Reciprocal Rank Fusion)
- pass to reranker
5) Learned sparse retrieval (SPLADE-style)
Sparse neural methods blend lexical matching + learned expansion. Useful when exact phrasing matters but keyword search alone is brittle.
6) Query transformation (rewrite, expand, decompose)
Two high-leverage patterns:
- HyDE: generate a “hypothetical answer doc”, embed that, retrieve neighbors
- Multi-query expansion: ask the LLM for 3–8 alternate queries, retrieve per query, fuse results
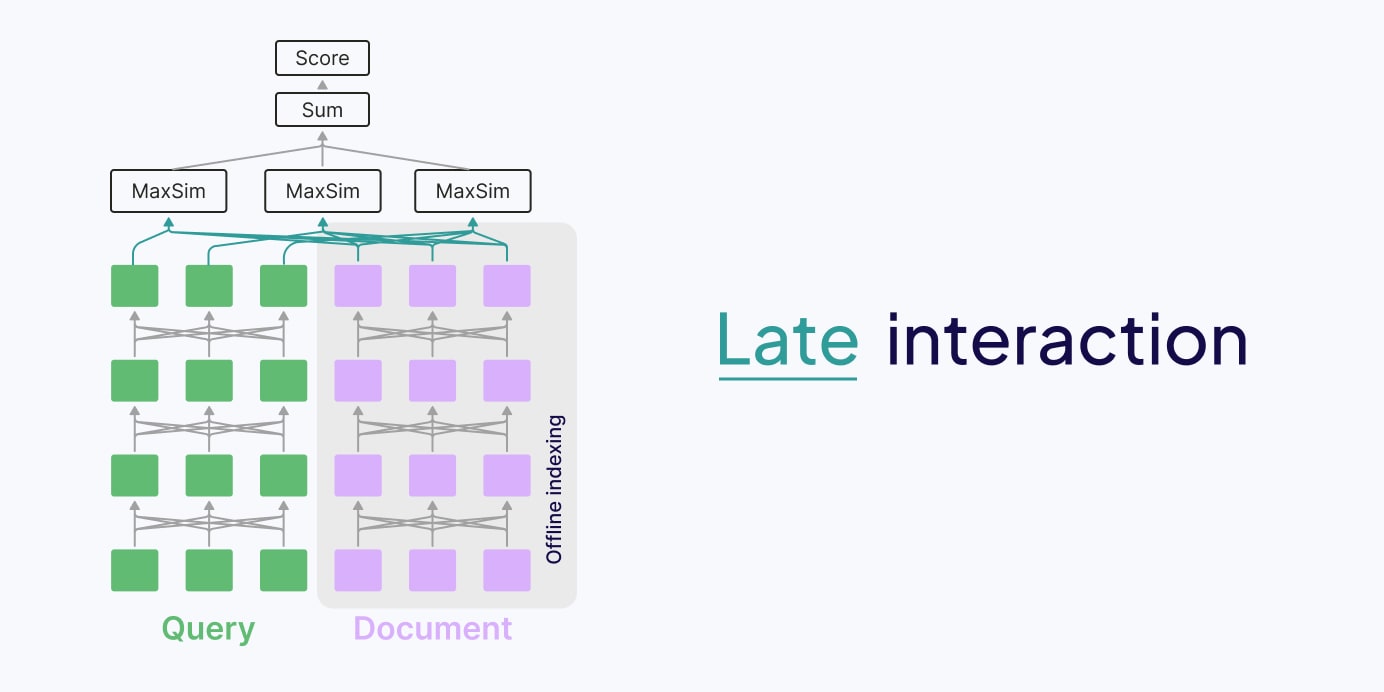
7) Late interaction / multi-vector retrieval (ColBERT-class)
Instead of one embedding per chunk, store token-level vectors and compute a richer similarity. Late interaction methods often win on “needle in haystack” retrieval, at higher storage/compute cost.
C) Post-retrieval upgrades (where accuracy jumps)
8) Reranking (cross-encoder or LLM reranker)
This is one of the most common “why didn’t we do this earlier?” upgrades.
Pattern:
- retrieve top 100 (cheap)
- rerank down to top 10 (accurate)
- generate answer from top 5–10
9) Context shaping: dedupe, diversify, compress
Even “correct” retrieval can overwhelm the model with duplicates/noise. Add a stage that:
- removes near-duplicates
- ensures diversity across sources/sections
- compresses chunks into “evidence bullets” (with citations)
D) Beyond flat retrieval: hierarchies and graphs
10) Hierarchical retrieval (RAPTOR-style)
Build a tree of:
- raw chunks at leaves
- clustered summaries at higher levels
Then at query time retrieve both:
- high-level summaries (for global context)
- leaf chunks (for evidence)

11) GraphRAG for “connect the dots” + global questions
GraphRAG builds an entity/relationship graph and community summaries so it can answer:
- “What are the main themes?”
- “What did X do?” when evidence is scattered
A classic failure is when baseline RAG retrieves chunks that are “related to the domain” but don’t mention the entity needed to answer.

E) Self-correcting RAG (robustness layer)
12) Retrieval evaluator + critique loop (Self-RAG / CRAG patterns)
Instead of blindly using top-k, SOTA systems:
- decide whether retrieval is needed
- evaluate retrieval quality
- trigger corrective actions: - retrieve again with different query - expand search scope (e.g., web / different index) - refuse/abstain when evidence is insufficient
This is how you reduce “confidently wrong” answers.
Why Most Teams Miss These RAG Performance Gains
Because vanilla RAG is easy to ship, and advanced RAG looks like “extra plumbing.”
But the performance gains come from:
- retrieval quality (hybrid + rerank + contextual embeddings)
- query intelligence (HyDE/multi-query/decomposition)
- non-flat memory (hierarchies/graphs)
- feedback loops (evaluation + regression tests)
In practice, teams often spend weeks tweaking prompts… when reranking + contextual embeddings would have moved the needle immediately.
A Pragmatic RAG Upgrade Path: Step-by-Step Implementation
Step 1 (1–2 days): add reranking
- retrieve top 50–200
- rerank to top 10
- measure accuracy lift
Step 2 (1–3 days): hybrid retrieval + RRF fusion
- BM25 + dense
- fuse rankings (RRF)
- rerank
Step 3 (2–7 days): contextual embeddings
- add chunk-level context pre-embedding
- keep original chunk text for citations
Step 4 (1–2 weeks): query rewriting / multi-query / HyDE
- multi-query + RRF
- or HyDE for “semantic gap” queries
Step 5 (2–6 weeks): hierarchical/graph retrieval + self-correction
- RAPTOR-like summaries or GraphRAG
- retrieval evaluator + retry/abstain policy
How to Evaluate RAG Performance: Metrics and Frameworks
Run systematic evaluations:
- retrieval metrics (context precision/recall, hit rate)
- generation metrics (faithfulness/groundedness, answer relevance)
- regression suites (same questions across versions)
Frameworks like RAGAS exist specifically for reference-free / pipeline evaluation.
References
- Anthropic – Contextual Retrieval
- Anthropic – Contextual Embeddings Guide
- RAG Survey (Naive to Advanced to Modular)
- Searching for Best Practices in RAG
- GraphRAG paper
- GraphRAG (open-source)
- RAPTOR paper
- Self-RAG paper
- Corrective RAG (CRAG) paper
- HyDE paper
- SPLADE paper
- ColBERTv2 paper
- Passage Reranking with BERT
- BEIR benchmark
- RAGAS paper